- Published on
風邪気味なので2024年末のインフルエンザの状況を確認してみた
- Authors

- Name
- Nomad Dev Life
インフルエンザ怖い
すっかり寒くなりましたが、皆様いかがお過ごしでしょうか?
12月といえば、何となくインフルエンザの患者が増える月、という印象があります。何かちょっとで風邪気味っぽい気がすると、まさかインフルでは…と思いながら葛根湯を飲む日々を送っております。
国内のインフルエンザの状況は、厚生労働省が週次でレポートをアップしているのをご存知でしょうか?今回はそれらのレポートをダウンロードして、12/20時点の状況を確認してみました。
データソース
今年のインフルエンザの状況は、以下のページにて週次でレポートされています。レポートはPDFファイルになっており、月曜日から次の日曜日までの状況を、次の金曜日にアップするようになっています。
今回は、このレポートの2ページ目に載っている"インフルエンザ定点当たり報告数・都道府県別"という表からデータを取得し、週単位でインフルエンザの報告数の推移を確認します。環境はGoogle Colabです。
レポートのダウンロード
まず、前記の厚生労働省のページにRequestsとBeautiful Soupを使ってアクセスし、インフルエンザの週次レポートをダウンロードします。
import requests
from bs4 import BeautifulSoup
import re
from datetime import datetime
import os
# URL to scrape
url = "https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/kenkou_iryou/kenkou/kekkaku-kansenshou01/houdou_00018.html"
# Send a GET request to the URL
response = requests.get(url)
response.raise_for_status()
# Parse the HTML content
soup = BeautifulSoup(response.content, "html.parser")
# Find all links containing the specified text
links = soup.find_all("a", string=re.compile("インフルエンザの発生状況について"))
# Extract the dates and links
date_link_pairs = []
for link in links:
href = link.get("href")
text = link.get_text()
# Extract date from the link text
date_match = re.search(r"\d{4}年\s?[0-9\d]{1,2}月\s*[0-9\d]{1,2}日", text)
if date_match:
date_str = date_match.group().replace(" ", "").replace('\xa0', '').translate(str.maketrans("0123456789", "0123456789"))
date_obj = datetime.strptime(date_str, "%Y年%m月%d日")
date_link_pairs.append((date_obj, href))
# Create the "pdfs" directory if it doesn't exist
os.makedirs("pdfs", exist_ok=True)
# Download all PDFs and save them with filenames based on the date
for date_obj, href in date_link_pairs:
# Complete the URL if it's relative
if not href.startswith("http"):
href = "https://www.mhlw.go.jp" + href
# Send a GET request to download the PDF
pdf_response = requests.get(href)
pdf_response.raise_for_status()
# Format the filename
filename = date_obj.strftime("%Y%m%d") + "_flu.pdf"
filepath = os.path.join("pdfs", filename)
# Save the PDF to a file
with open(filepath, "wb") as pdf_file:
pdf_file.write(pdf_response.content)
リンクの文字列に含まれている日付をyyyyMMddに変換し、ダウンロードしたPDFのファイル名に使っています。ダウンロードしたPDFの置き場所はpdfsというフォルダの配下にしています。
少し面倒だったのが、リンクの文字列に含まれている日付文字列の正規化です。月や日付の数値が1桁の場合はspace + 全角数字が使用されています。また、0xa0が含まれていることもあり、取り除く必要がありました。
レポートPDFから都道府県別の報告数を取り出す
次に、レポートPDFから都道府県別の報告数を取り出します。取り出したいデータはPDFの2ページ目にあります。
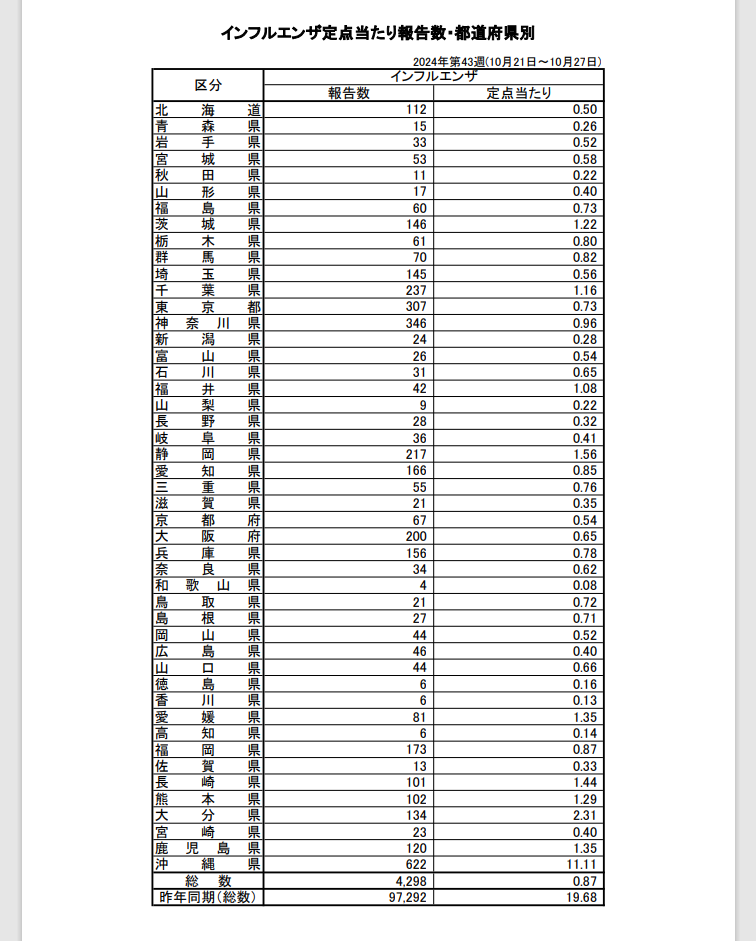
今回はtabula-pyを使ってこの部分を取り出し、PandasのDataframeに変換します。
import tabula
import pandas as pd
import os
# Load all PDF under "pdfs" folder
pdf_files = [f for f in os.listdir("pdfs") if f.endswith(".pdf")]
dfs = []
for pdf_file in pdf_files:
print(f'pdf_file: {pdf_file}')
if pdf_file == '20241108_flu.pdf':
pages = "3"
else:
pages = "2"
tables = tabula.read_pdf(os.path.join("pdfs", pdf_file), pages=pages, multiple_tables=False)
if len(tables) == 0:
continue
df = tables[0].drop(index=[0, 48, 49])
df.columns = ['pref', 'reported', 'ratio']
df['date'] = pd.to_datetime(pdf_file.split("_")[0])
df['reported'] = pd.to_numeric(df['reported'].str.replace(',', ''), errors='coerce')
print(f"Loaded {len(df)} tables from {pdf_file}")
dfs.append(df)
# Integrate dfs to one dataframe
df = pd.concat(dfs, ignore_index=True)
print(df)
tabula.read_pdfでPDFをロードし、2ページ目の表の内容をDataframeとして取り出します。dateはdatetime型に、reported(インフルエンザの報告数)は数値型に変換しています。prefは都道府県名です。
20241108_flu.pdfだけ3ページ目に当該表があるので、ファイル名を見て参照ページを変えるようにしています。こういうところに泣かされますね...
最後に、それぞれのPDFから取得したDataframeをpd.concatで一つにまとめています。
インフルエンザの報告数をグラフで表示する
Dataframeを取得できたので、その内容をグラフに表示します。まずは、週次の報告数の遷移を見てみました。
import plotly.express as px
fig = px.bar(
df,
x='date',
y='reported',
color='pref',
title="都道府県別 インフルエンザ報告数 都道府県積み上げ",
labels={'reported': '報告数', 'pref': '都道府県'}
)
fig.show()
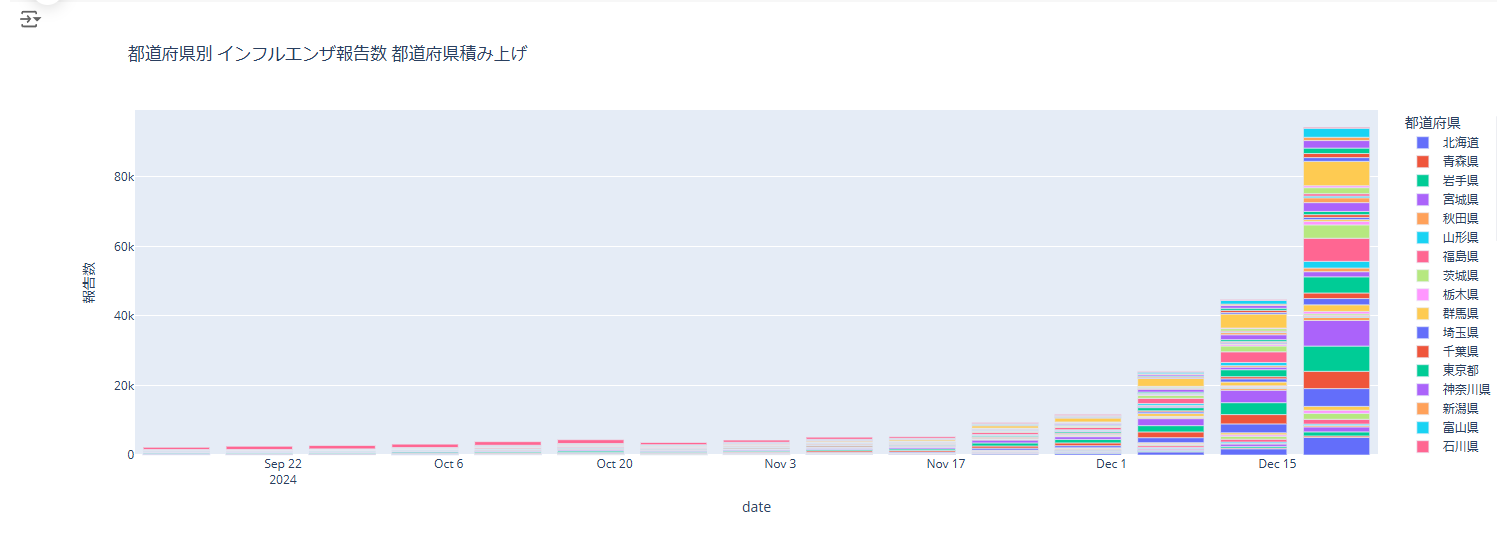
12月に入って報告数が大分増加していることが分かります。この週次レポートは先週分の実績なのですが、このグラフを見る限り、今週はもっと増加している可能性が高いですね。怖い…。
次に、都道府県別の報告数の推移を見てみましょう。
fig = px.bar(
df,
x='pref', # X軸: 都道府県
y='reported', # Y軸: 報告数
color='date',
title='都道府県別 インフルエンザ報告数 週次積み上げ',
labels={'reported': '報告数', 'pref': '都道府県'},
category_orders={'date': sorted(df['date'].unique(), reverse=False)}
)
fig.show()
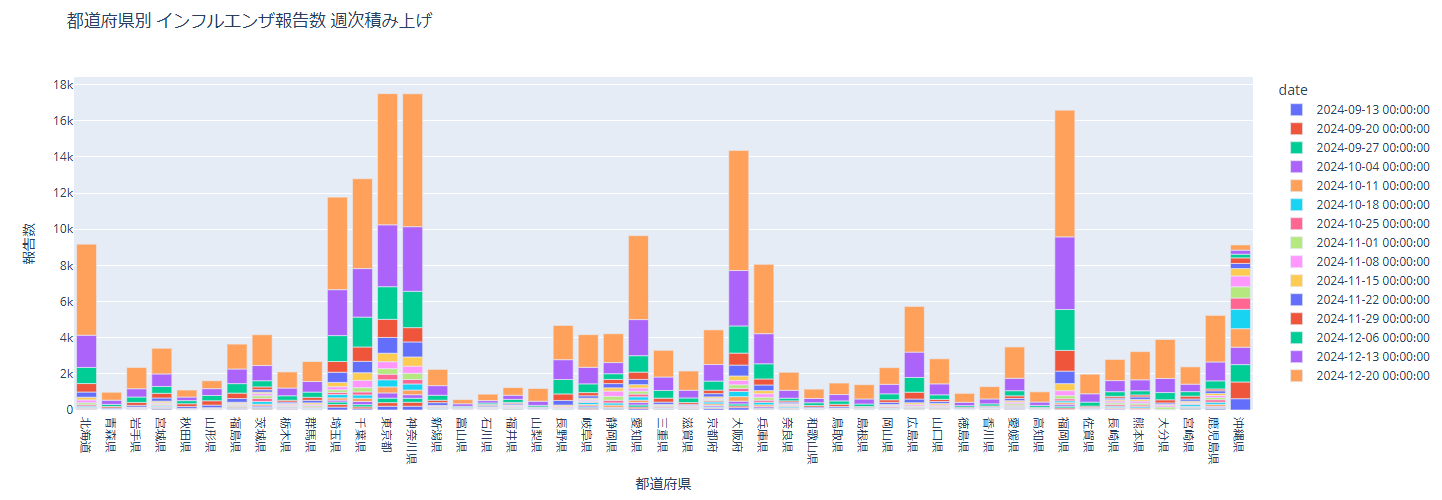
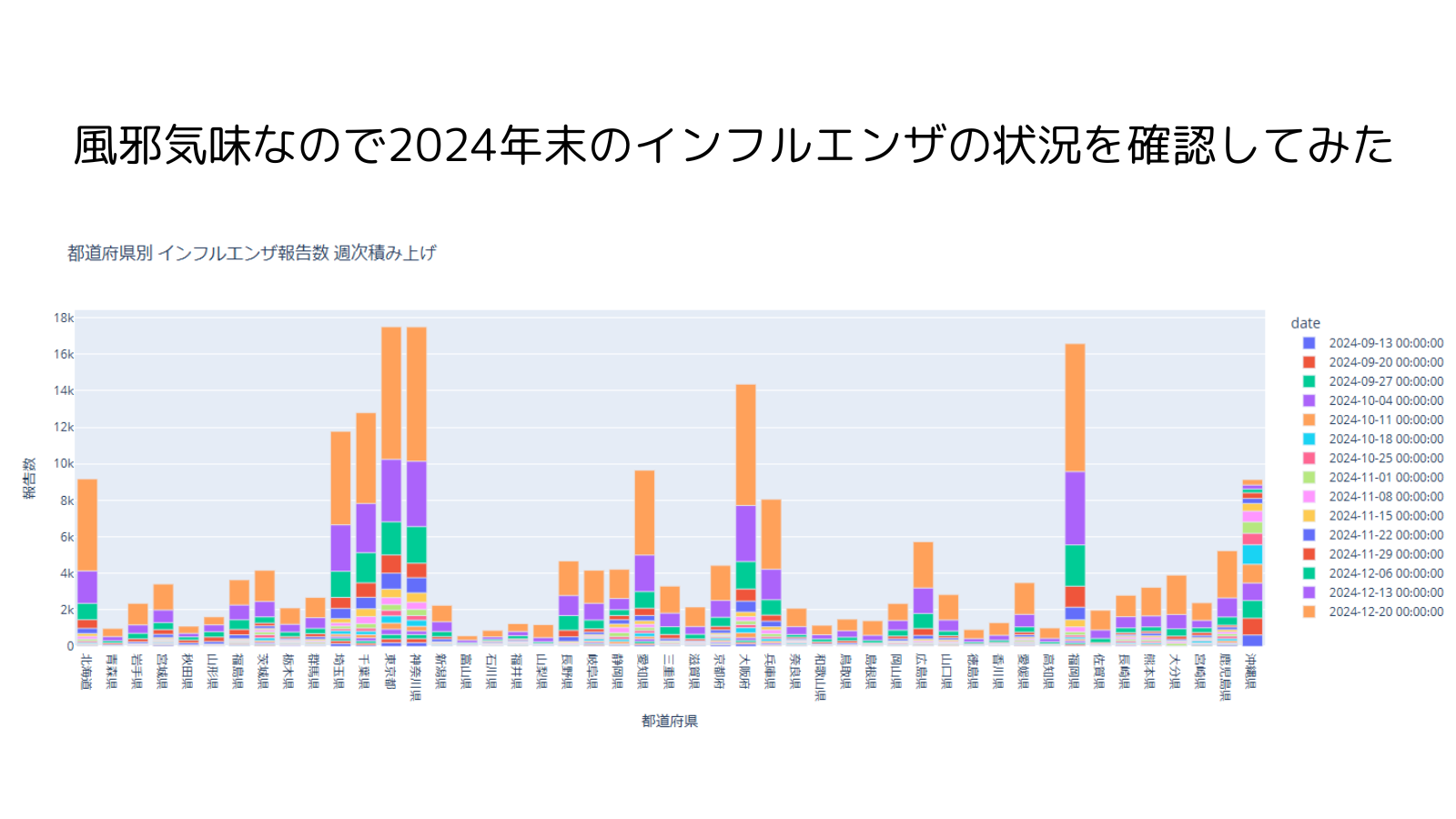
埼玉、千葉、東京、神奈川、大阪、福岡が報告数が多くなってきていることが分かります。沖縄は10月頃に一度ピークが来ているようですね。
おわりに
インフルエンザの週次レポートをロードし、インフルエンザの報告数の推移を見てみました。今回使ったコードは以下にあります。
インフルエンザの報告数は12月に入ってからかなり増加傾向にあるので、引き続き推移を見守りながら、年末年始はインフルエンザに気を付けながら生活したいと思います。皆様もご自愛ください...。